When Medium was first launched, it stood out among other blogging platforms for its minimalist design. For long, this elegant design has been used for delivering content created on its platform. This is about to change.
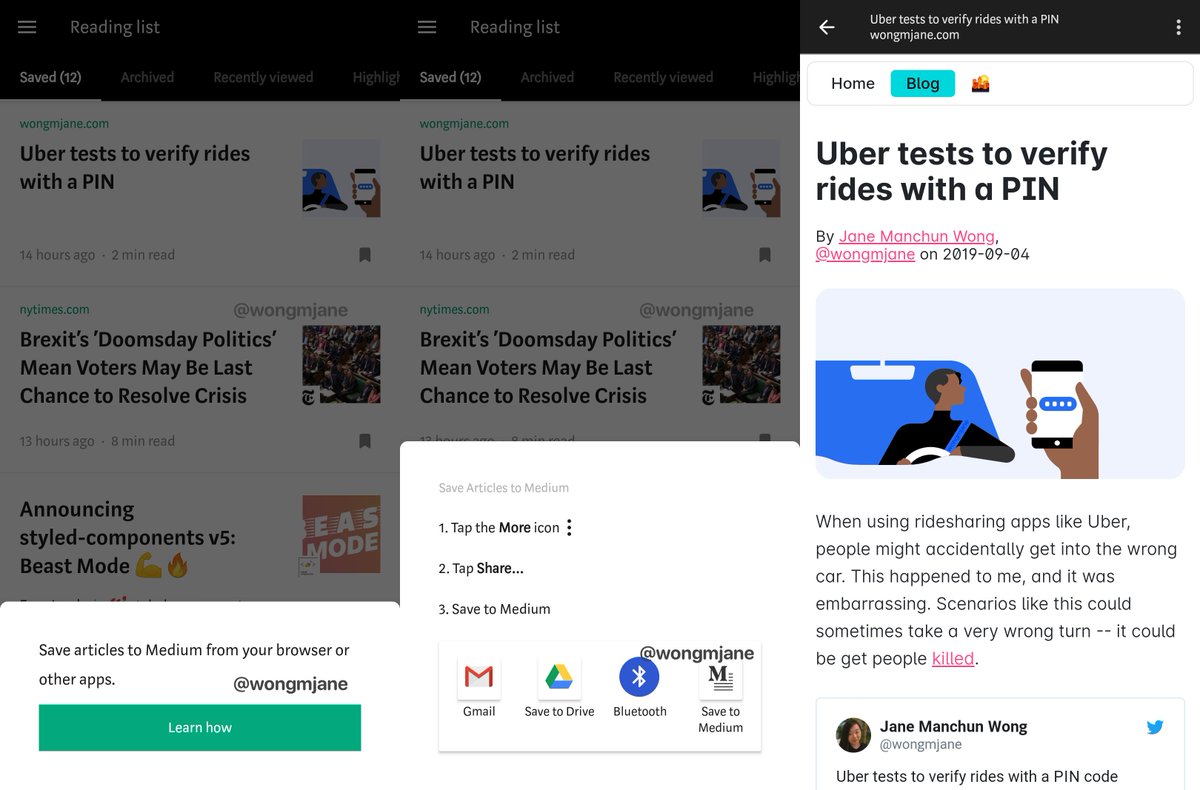
It appears to me that Medium wants to double as a Reader app in an experiment. This unreleased feature is called “Save to Medium”, similar to how Instapaper works. I came across it by reverse-engineering Medium’s Android app, and then analyzing the code underneath the app and its network traffic.

 (opens in new window)
(opens in new window)With “Save to Medium”, users can share articles from web browsers or other apps. This ascends their user experience beyond Medium’s own platform, allowing users to consume articles created elsewhere clutter-free and ad-free, without leaving the Medium app.
To test out this feature, I opened the browser app on my phone to share a link of my blog post, and another link of a news article from The New York Times, to Medium app. The later is published behind a soft paywall. These two articles then showed up on the “Reading list” section in Medium app. Tapping them from the Reading List opens an in-app browser of the webpages.
Being unsatisfied with this observation, I then monitored the network traffic between Medium’s app and the internet to observe how the “Save to Medium” feature works underneath.
This is about to get a lot more interesting and a bit more technical! :D
Honeypoting the web scarper
It appears that Medium app sends a network request with the shared URL to their server endpoint to scrape the webpage from their proxy server:
To observe the web-scraping behavior, I set up a honeypot web server and sent a server request to Medium’s endpoint to make their proxy server to scrape this honeypot webpage. Few observations about the scraper’s behavior: (1) It does not fetch subresources, which means external images, scripts, etc are not scraped (2) It does not execute JavaScript
And the User-Agent strings are as follows:
Attmpted Server-Side Request Forgery
It appears the proxy/scrapers are on the AWS, so I tried to send a request to the Medium server proxy endpoint with the IP address within their internal network on AWS to see if it can result in scraping their own server data. This server request is blocked by Cloudflare.
In my second attempt, I made my honeypot server to redirect any incoming requests to the AWS internal IP address. This attempt also failed due to it returning no data.
Based on these two failed attempts, there does not seem to be security vulnerabilities with Medium’s web-scrapers.
“Syndication”
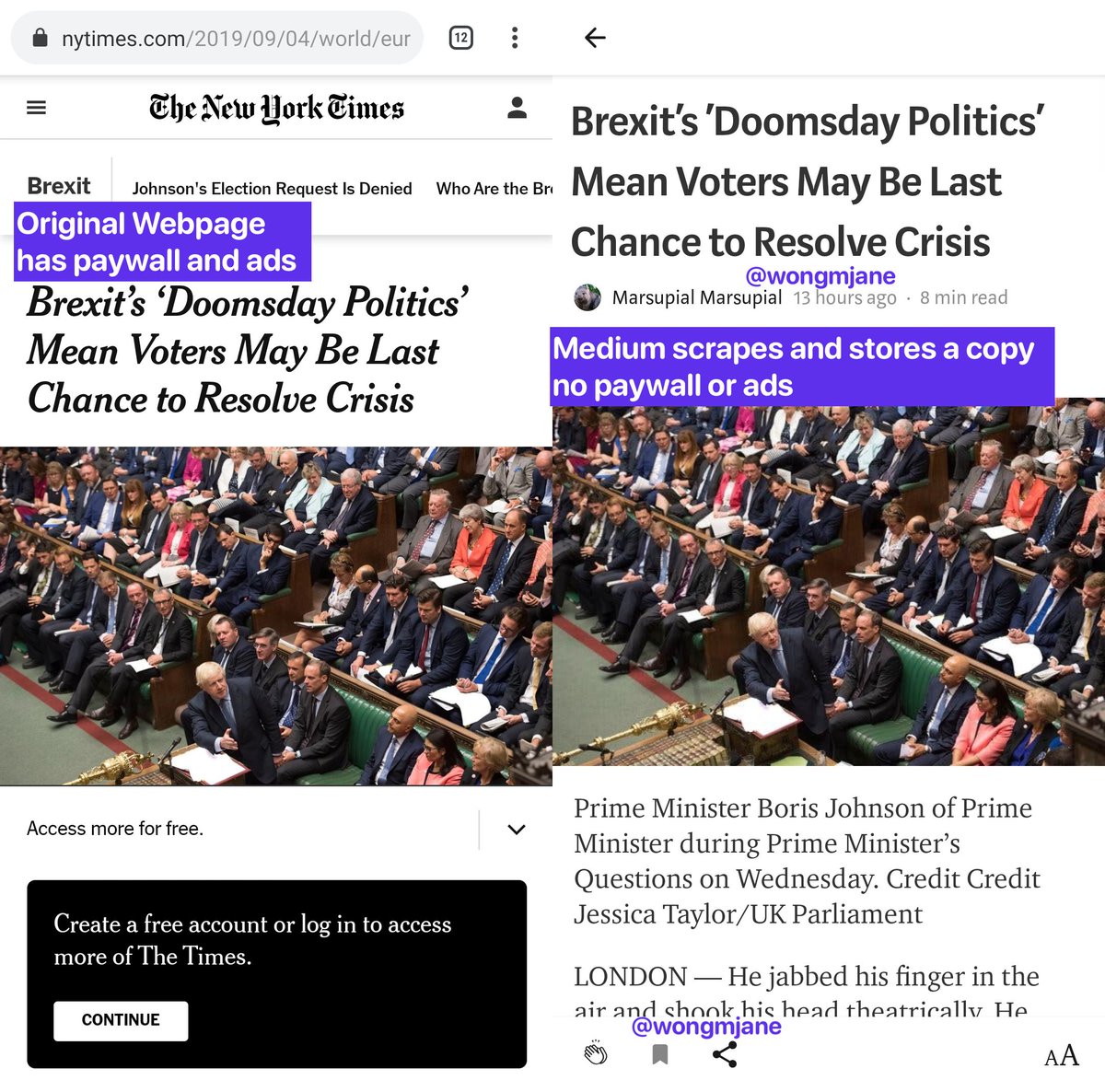
Despite tapping a saved external article on Medium app’s Reading List opens an in-app browser of the webpage, I noticed that Medium creates a new unlisted Story on Medium based on the content scraped from the webpage.
 (opens in new window)
(opens in new window)These copies are created as Medium Stories and they are not the original webpages, meaning while the reading experience might be more clutter-free, it lacks the ads and paywalls that might originally exist on the webpage.
The lack of ads and (soft) paywall enforcements means the current unreleased version of “Save to Medium” could be used as a tool to bypass the paywall and filter out ads.
I am not sure how this will sit from a media / news publisher’s perspective that relies on ads and subscriptions.
Some might argue there are existing reader/bookmarking apps that do the same scrapping and ads/paywall removal. But let’s not forget that Medium is a blogging/publishing platform with their own subscription model and paywall-ed content.
Don’t get me wrong. I am sure a lot of people like free stuff . But I just find it hard to justify removing ads / bypassing paywalls from external content while enforcing paywall for some Medium stories.
Unremovable from Medium’s server
These unlisted Stories are labeled as “proxy post” on Medium’s server and are not created under the user’s Medium account, but a dummy account called “Marsupial Marsupial”, in which “Marsupial” happens to be the code name of this feature.
There does not seem to be an option to remove these proxy Stories. Even if I remove such item from my Medium’s Reading List, the Story remains undeleted. These proxy Stories are publicly accessible, logging in is not required.
Conclusion
After all, the “Save to Medium” feature is currently unreleased and under development, which could explain the rough edges mentioned above. Rough edges are usually polished away in the future. Experimental features could come and go.
If I may suggest, there are many ways for the media and news publishers to collaborate. Blocking Medium’s “Save To Medium” scraper from accessing the site should be the last resort.
 (opens in new window)
(opens in new window)I would recommend looking at how other news reader apps work. Some of them enforce the soft paywall and allow linking the reader app with the news subscription account.
Disclaimer: I tested this feature with a news article from The New York Times in good faith for the sole purpose of informational purpose on testing and demonstrating whether the current unreleased version of “Save to Medium” feature can bypass the paywall. I have been a subscriber on The New York Times for several months prior to the time of writing.